Preprocessing techniques in Natural Language Processing (NLP) help prepare and clean raw data, making it usable for analysis models. These preliminary steps, often invisible but crucial, are key to transforming vast amounts of unstructured data into actionable information. Whether it's cleaning raw text, normalizing formats, or removing unnecessary noise, preprocessing ensures the optimal performance of NLP models.
In this article, we demystify these techniques and their impact on the quality of results. Mastering them allows for optimal performance in projects.
Table of content
TogglePreprocessing techniques in Natural Language Processing (NLP): A key step for model performance
The main objective of the NLP (Natural Language Processing) is to give computers the ability to understand, process, and analyze texts written in human languages.
The way computers understand language is quite different from ours. A machine doesn't know French, English, or even Wolof; it only understands the binary system. (numbers 1 and 0).

To give a computer the ability to understand texts written in human languages, we must first perform the translation. of these texts into the langage machine ».
Before addressing this translation step, it is necessary, however, to perform the preprocessing. of this textual data.
Why is preprocessing important?
Indeed, when we write texts (like this one), we use various elements to specify the different things that happen, but also to convey other information, which may not always be useful to the machine.
For example, a « . » to specify the end of a sentence or a capital letter to mark the beginning of another. The conjugation of a verb in a tense to specify the time of the event, the use of articles to specify gender, the use of conjunctions, etc.
You see what I mean! We use a set of details to make ourselves more understandable to the reader.
However, to extract information from a text, a computer doesn't (always) need all these details. They generally represent noise for it and can make the processing much more complex the understanding of a text.
So, to simplify things, there are a few preprocessing steps that are necessary.
In this episode, we will explore some of them, try to explain them, and implement a few.
Before we begin, it is important to clarify that there is no consensus regarding what should be done in this pre-processing step. It generally depends on the task at hand. Some techniques may be useful, for example, in more problematic text classification when we want to do sentiment analysis.
Without further ado, let's start with the most manageable pre-treatment methods.
Lower case, accents, contractions, special characters.
3. The main pre-processing techniques in NLP
The capital letters are usually unnecessary and can create confusion. For example, let's say that in a text we find the word « "sun" written in two different ways: " "sun" and "Soleil". The machine may think that these are two different words because computers are case sensitive. This basically means that A and a are not represented the same way at the computer level (ASCII) . In such cases, it is therefore preferable that all your words are in lower case.
The accents can also cause trouble. If we take a similar example, création and "creation" represent two different words to the computer.
Some languages (like English) also contain contractions. « He is » which is considered two words if contracted into « he’s« is just a word for the machine. To remedy this ce problem, he is It is often useful to have a dictionary containing the different contractions of a language and their corrections. The special characters are often superfluous – even if in some cases they may be needed (sentiment analysis) – otherwise it is better to remove them.
Les Stopwords (mots vides)
In computing, stop words (stopwords) are words that are filtered before or after natural language data processing (NLP). Although the term "stop words" generally refers to the most common words in a language, there is no single universal list of stop words used by all natural language processing tools. (Wikipedia).
Indeed, depending on the NLP tasks, certain words and expressions are useless in the context of the work to be carried out.
Suppose we want to do a a simple similarity test between documents written in French. To do this, we have the idea of counting for each document, the 15 most frequent words. If two documents have more than 7 words in common in their most frequent words we will assume that they are similar, otherwise they are different.
This is a fairly simple and trivial process, similarity between documents requires much more than these steps, however, as an example, let's try to keep it simple.
If I use texts in their raw form without removing the stopwords, we would risk ending up with only similar texts. Why?
It’s simple, the 45 to 50 most frequent words in the French language represent on average 50% of a text.
And if we go further, the 600 most frequent words in the French language represent 90% of a text.
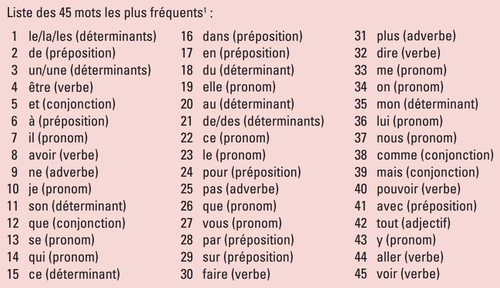
You now see the usefulness of removing in this case the empty words which could distort the similarity.
There are lists (not very extensive) of stop words in French within libraries (such as NLTK for Python) or on the Internet. As it differs depending on the purposes, it is best to use these lists as a starting point and add or remove words as needed.
Stemming (stemming or desuffixation)
In linguistic morphology and information retrieval, the stemming is the process of reducing inflected (or sometimes derived) words to their stem, base, or root – usually a written form.Wikipedia)
In simpler terms, the stemming is the process of reducing a word to its “root.”
For example in french : marcher, marches, marchons, marcheur, … will be reduced to march and they will thus share the same meaning in the text.
Search engines use it when we make a query to display more results and/or correct errors in your query (query expansion).
Let’s say you’ve been living in a cave for the last few decades and now you want to watch Star Wars (there are so many) and you’re not very good at French grammar like me. You search for “ quelles ordre regardait stars war »
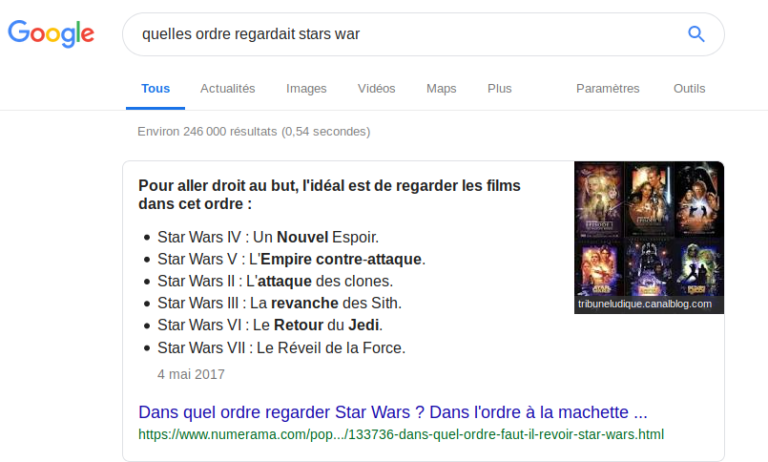
As you can see, the first answer is the one I was looking for even though I didn't enter a grammatically correct query.
Search engines use different techniques to “expand” and make your query better and one of them is Stemming.
There are different algorithms that implement the stemming : Lovins Stemmer, Porter Stemmer, Paice Stemmer, etc. Everyone has their own way of getting the stemma (root) in a word.
Most of these algorithms work with the English language.
However, there are algorithms for stemming which have been implemented for the French and the library NLTK Python has a Stemmer in French.
Let's test this Stemmer with a sentence from Stephen King's The Long Walk:
Ils marchaient dans l’obscurité pluvieuse comme des fantômes décharnés, et Garraty n’aimait pas les regarder. C’étaient des morts-vivants.
After passing it to the Stemmer of NLTK we get the following result:
il march dan l’obscur pluvieux comm de fantôm décharnes et garraty n’aim pas le regarder c’et de morts-vivants
Reading the results after extraction, you can clearly see that after reducing the words, there are several that do not exist in the French dictionary: fantom,aim,….
As to why this might happen, this is the best answer I could find online:
It is often considered a gross error that a stemming algorithm does not leave a real word after removing the stem. But the goal of stemming is to gather the different forms of a word, not to match a word to its ‘paradigmatic’ form. Source
In summary, the Stemming therefore serves to group together in a “bully”several words sharing the same meaning by removing gender, number, conjugation, etc.
Algorithms are not, however, perfect. They can work for some cases and for others, group together words that do not share the same meaning.
PS : Stemming is not a concept that applies to all languages. It is not, for example, applicable in Chinese. But for languages of the Indo-European group a common pattern of word structure emerges. Assuming that words are written from left to right, the stem or root of a word is on the left, and zero or more suffixes may be added on the right. Source
Lemmatisation
In computational linguistics, lemmatization is the algorithmic process of determining the lemma of a word based on its intended meaning.( Wikipedia )
In many languages, words appear in multiple inflected forms. For example, in anglais français, the verb marcher may appear as marchera, marché, marcheront , etc. The basic form “ marcher », which one might find in a dictionary, is called the lemma of the word.
Here, the main goal of the lemmatization, is to group together the different words of a text which share the same “meaning” into a single word which is the lemma sans pour autant créer de « new » words like what is done in the case of the stemming.
However, the lemmatizers are much more difficult to create because you need a dictionary that contains most of the words in your language and you also need to know the nature of the word in question: a verb and a noun are lemmatized in a different way.
Search engines can also use lemmatization instead of stemming, it provides in some cases more precise results but is more difficult to implement.
As for the Stemming, NLTK also has a lemmatizer for the French.
Tokenization
Processing a large chunk of text is usually not the best way to go about it. As they always say "divide and conquer". The same concept applies to NLP tasks as well.
When we have texts, we separate them into different tokens and each token represents a word. It will be easier to process (do stemming or lemmatization) and filter out unnecessary tokens (like special characters or stop words).
N-gram
A n-gram is a contiguous sequence of n elements of a given sample of text. (Wikipedia)
The n-gram are therefore sequences of words formed from a text. Here N describes the number of words combined together.
If you had the sentence:
« c’est fini Anakin, j’ai l’avantage sur toi ! »
Each small square represents a token (word/1-gram), which is practically the tokenization of the sentence. Thus, the tokenization can be considered as a special case of n-gram where N=1.
A 2-n-gram also called bigram from the same sentence would produce this:

The n-gram can be used to find out which sequence of words is most common. Like this site Web that calculates the most common trigrams in French:
1-Gram | Occurrence | 2-Grams | Occurence | 3-Grams | Occurence |
of | 1024824 | de la | 132940 | il y a | 8903 |
la | 602084 | à la | 56794 | et de la | 4796 |
and | 563643 | et de | 37743 | il y avait | 4397 |
le | 411923 | dans la | 30090 | que je ne | 3894 |
Table: Analysis of n-grams and their occurrence in a text corpus
POS tagging
In corpus linguistics, the POS tagging (POS tagging or PoS or POST tagging), also called grammatical tagging or word category disambiguation, is the process of marking a word in a text (corpus) as corresponding to a particular part of speech, according to its definition and context, that is, its relationship to neighboring and related words in a sentence, paragraph, phrase, etc. A simplified form of this notion is commonly taught to school-age children, in the identification of words as nouns, verbs, adjectives, adverbs, etc. (Wikipédia)
So, POS tagging is like identifying the nature of each word in a text.
It is very useful, especially in lemmatization, because you need to know what the word is before you try to lemmatize it. For example, the way you lemmatisez Nouns and verbs may differ because they express plurality or gender in a different way.
Let's take our same example sentence, after passing it to a POS tagger de Python, nous obtenons :
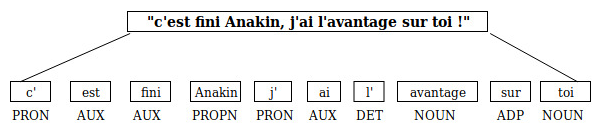
It is also useful in translation tasks. Let’s take this simple example I found online:
I fish a fish .
Translated into French you have:
je pêche un poisson.
The word “fish” has two meanings here. It refers to the verb to fish (pêcher) when used after a subject and when following an article, it refers to the word fish (poisson). It is therefore necessary to have a tool to differentiate the two.
However, it will be very tedious to do this task in a very long text. There are libraries that allow you to do this work in languages such as French or English. It is also possible to use techniques of Deep Learning to carry out this work.
Implementation in Python
We will now try to implement some of these techniques in the Python language.
To do this, let's try a simple exercise: take a book and study its most important words and bigrams to briefly grasp what the book is about.
If you don't like codes, you can skip this part and go to the conclusion
Let's first download Voltaire's Zadig book from the Gunteberg Project Library.
[python]
zadig_response = requests.get(‘https://www.gutenberg.org/cache/epub/4647/pg4647.txt’)
zadig_data = zadig_response.text
# Each book comes with licenses that we are not really interested in so we will remove this part
zadig_data = zadig_data.split(‘*******’)[2]
[/python]
Let's first download Voltaire's Zadig book from the Gunteberg Project Library.
[python]
def process_data(data):
#Let's put all the words in the book in lowercase
data = data.lower()
#Take only letters and numbers and remove all special characters
pattern = r'[^a-zA-z0-9\s]’
data = re.sub(pattern, », data)
#Remove all stop words (stopwords) like ‘les’, ‘du’, ……. and tokenize the text
stop_words = set(stopwords.words(‘french’))
stop_words.add(‘[‘)
stop_words.add(‘]’)
stop_words.add(‘les’)
stop_words.add(‘a’)
word_tokens = nltk.word_tokenize(data)
words = [w for w in word_tokens if not unidecode(w) in stop_words]
#remove all accents if they exist
data = unicodedata.normalize(‘NFKD’,data).encode(‘ascii’, ‘ignore’).decode(‘utf-8’, ‘ignore’)
#Create a stemmer in French
fs = FrenchStemmer()
text_stems = [fs.stem(word) for word in words]
#Create a lemmatizer in French
lemmatizer = FrenchLefffLemmatizer()
text_lemms = [lemmatizer.lemmatize(word,’v’) for word in words]
return (text_stems, text_lemms)
[/python]
Then we count the most frequent words in the text first for the text passed through a Stemmer:
[python]
#Now let's count the words for lemmas and stems
text_stems,text_lems = process_data(zadig_data)
count = Counter(text_stems)
print(‘Most used words in Zadig with stems:’)
for word in count.most_common(15):
print (word)
[/python]

For words passed through a Lemmatizer:
[python]
count = Counter(text_lems)
print(‘Most used words in Zadig with lemmas:’)
for word in count.most_common(15):
print (word)
[/python]

Just for fun, let's count the most common bigrams:
[python]
ngram_counts = Counter(ngrams(text_lems, 2))
print(‘ the 10 most frequent bigrams : ‘)
for word in ngram_counts.most_common(10):
print (word)
[/python]

In conclusion
We have reviewed the main methods of text data pre-processing, they are used to facilitate the translation of a text written in human language into machine language.
La plus grande remarque faite lors des recherches pour cet article est que la plupart de ces techniques n’existent que pour les langues main and are only "perfect" for English in general. For less extensive languages, such as Wolof, it becomes essential to be able to implement all these techniques in order to effectively process texts written using them.
Do not hesitate to read our article on The foundations of NLP and deep learning.