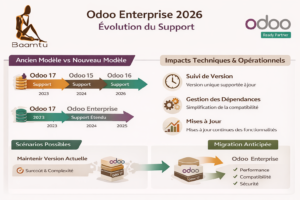
Support Odoo Enterprise : impacts techniques 2026
Depuis le 10 juillet 2025, Odoo a annoncé une évolution majeure de sa politique de support : toutes les versions...
Lire tout
Migration Odoo : Comment choisir le bon partenaire ?
Depuis juillet 2025, Odoo a annoncé un changement majeur de sa politique de support : les versions Enterprise âgées de...
Lire tout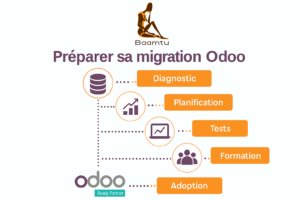
Odoo Enterprise : préparer la migration avant Avril 2026
Préparer la migration sur Odoo avant avril 2026 est nécessaire avec les changements de politique de support et la majoration...
Lire tout
Odoo : la nouvelle politique de support 2026
Depuis le 10 juillet 2025, Odoo a annoncé une évolution majeure de sa politique de support : désormais, toutes les...
Lire tout