
Les techniques de prétraitement en traitement du langage naturel permettent de préparer et d’assainir les données brutes pour les rendre exploitables par les modèles d’analyse. Ces étapes préalables, souvent invisibles mais cruciales, sont la clé pour transformer des masses de données non structurées en informations exploitables. Qu’il s’agisse de nettoyer des textes bruts, de normaliser des formats ou d’éliminer le bruit inutile, le prétraitement permet de maximiser la performance des modèles NLP.
Dans cet article, nous démystifions ces techniques, leur impact sur la qualité des résultats. Les maîtriser permet d’obtenir des performances optimales dans les projets.
Table des matières
Toggle1. Techniques de prétraitement en traitement du langage naturel (NLP) : Une étape clé pour la performance des modèles
L’objectif principal du NLP (Natural Language Processing) est de donner aux ordinateurs la capacité de comprendre, traiter, analyser des textes écrits dans des langues humaines.
La manière dont les ordinateurs comprennent le langage est assez différente de la nôtre. Une machine ne connaît pas le Français, l’Anglais ou encore le Wolof, elle ne comprend que le binaire ( les chiffres 1 et 0).

Pour donner à un ordinateur la capacité de comprendre des textes écrits dans des langues humaines, il faut d’abord faire la traduction de ces dits textes vers le « langage machine ».
Avant d’aborder cette étape de traduction, il est nécessaire, cependant, de faire le prétraitement de ces données textuelles.
2. Pourquoi le Prétraitement est-il important ?
En effet, lorsque nous écrivons des textes (comme celui-ci), nous utilisons divers éléments pour spécifier les différentes choses qui se produisent, mais aussi relayer d’autres informations, qui peuvent ne pas toujours être utiles à la machine.
Par exemple, un « . » pour spécifier la fin d’une phrase ou encore une majuscule pour marquer le début d’une autre. La conjugaison d’un verbe à un temps pour préciser le moment de l’événement, l’emploi des articles pour spécifier le genre, l’emploi de conjonctions, etc.
Vous voyez ce que je veux dire! Nous utilisons un ensemble de détails pour nous rendre plus compréhensibles vis-à -vis du lecteur.
Cependant, pour pouvoir tirer des informations d’un texte, un ordinateur n’a pas (toujours) besoin de tous ces détails. Cela ne représente, en général, que du bruit pour lui et peut rendre beaucoup plus complexe la compréhension d’un texte.
Donc, pour simplifier les choses, il y a quelques étapes de prétraitement qui sont nécessaires.
Dans cet épisode, nous allons explorer certaines d’entre elles, essayer de les expliquer et d’en implémenter certaines.
Avant de commencer, il est important de préciser qu’il n’y a pas de consensus en ce qui concerne ce qui doit être fait dans cette étape de pré traitement. Cela dépend, en général, de la tâche à accomplir. Certaines techniques peuvent être utiles, par exemple, lors d’une classification de texte mais problématique lorsque l’on veut faire de l’analyse de sentiment.
Sans plus tarder, commençons par les méthodes de pré traitements les plus faciles à gérer.
Minuscules, accents, contractions, caractères spéciaux.
3.Les principales techniques de prétraitement en NLP
Les majuscules sont généralement inutiles et peuvent créer de la confusion. Par exemple, disons que dans un texte nous retrouvons avec le mot « soleil » écrit de deux façons différentes: « soleil » et « Soleil« . La machine peut croire qu’il s’agit de deux mots différents parce que les ordinateurs sont sensibles à la casse. Cela signifie essentiellement que A et a ne sont pas représentés de la même manière au niveau de l’ordinateur (ASCII) . Dans ce genre de cas, il est donc préférable que tous vos mots soient en minuscules.
Les accents peuvent également semer le trouble. Si on prend un exemple similaire « création » et « creation » représentent deux mots différents pour l’ordinateur.
Certaines langues (comme l’anglais) contiennent aussi des contractions. « He is » qui est considéré comme deux mots s’il est contracté en « he’s« ne représente qu’un mot pour la machine. Pour remédier à ce problème, il est souvent utile de disposer un dictionnaire contenant les différentes contractions d’une langue et leur correction. Les caractères spéciaux sont souvent superflus – même si dans certains cas on peut en avoir besoin (analyse de sentiment) – il est préférable de les enlever dans le cas contraire.
Les Stopwords (mots vides)
En informatique, les mots vides (stopwords) sont des mots qui sont filtrés avant ou après le traitement des données en langue naturelle (NLP). Bien que le terme « mots vides » désigne généralement les mots les plus courants dans une langue, il n’existe pas de liste universelle unique des mots vides utilisés par tous les outils de traitement du langage naturel. (Wikipedia).
En effet, en fonction des tâches NLP, certains mots et expressions sont inutiles dans le cadre du travail à réaliser.
Supposons que nous voulions faire une un test de similarité simple entre des documents écrits en Français. Pour effectuer cela, nous avons comme idée de compter pour chaque document, les 15 mots les plus fréquents. Si deux documents ont plus de 7 mots en commun dans leurs mots les plus fréquents on supposera qu’ils sont similaires, sinon ils sont différents.
Il s’agit d’un processus assez simple et trivial, la similarité entre des documents nécessite beaucoup plus que ces étapes là, en guise d’exemple cependant, essayons de faire simple.
Si j’utilise des textes dans leur forme brut sans enlever les stopwords, on risquerait de ne se retrouver qu’avec des textes similaires. Pourquoi ?
C’est simple, les 45 à 50 mots les plus fréquents de la langue française représentent en moyenne 50% d’un texte.
Et si on pousse plus loin, les 600 mots les plus fréquents de la langue française représentent 90% d’un texte.
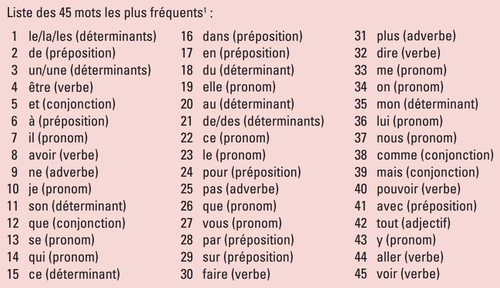
Vous voyez maintenant l’utilité d’enlever dans ce cas-ci les mots vides qui risqueraient de fausser la similarité.
Il existe, des listes (pas très fournies) de stop words en Français au sein des bibliothèques (telle que NLTK pour Python) ou sur Internet. Comme elle diffère en fonction des objectifs, il est préférable d’utiliser ces listes comme point de départ et d’y ajouter ou supprimer des mots au besoin.
Stemming (racinisation ou désuffixation)
Dans la morphologie linguistique et la recherche d’information, le stemming est le processus qui consiste à réduire les mots infléchis (ou parfois dérivés) à leur souche, leur base ou leur racine – généralement une forme écrite. (Wikipedia)
En termes plus simples, le stemming est le processus qui consiste à réduire un mot à sa « racine ».
Par exemple : marcher, marches, marchons, marcheur, … seront réduits à march et ils partageront ainsi la même signification dans le texte.
Les moteurs de recherche l’utilisent lorsque nous faisons une requête pour afficher plus de résultats et/ou corriger des erreurs sur votre requête (query expansion).
Disons que vous avez vécu dans une grotte pendant les dernières décennies et maintenant vous voulez regarder les Star Wars (il y en a tellement) et vous n’êtes pas très bon en grammaire Français comme moi. Vous cherchez « quelles ordre regardait stars war »
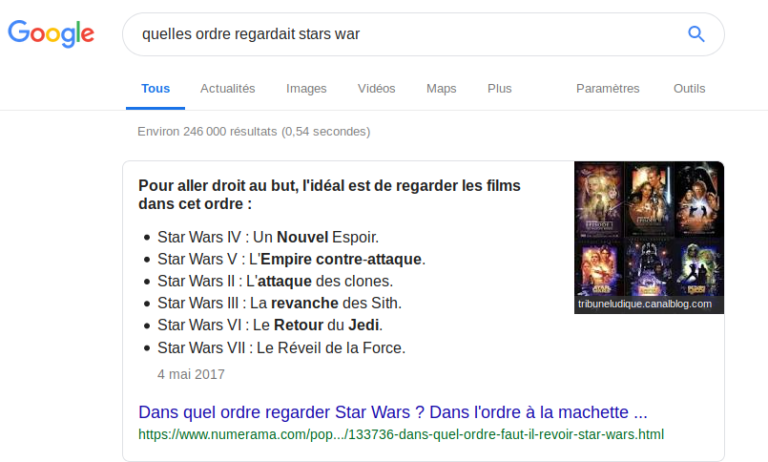
Comme vous pouvez le voir, la première réponse est celle que je cherchais même si je n’ai pas entré une requête grammaticalement correcte.
Les moteurs de recherche utilisent différentes techniques pour « étendre » et rendre votre requête meilleure et l’une d’elles est Stemming.
Il existe différents algorithmes qui implémentent le stemming : Lovins Stemmer, Porter Stemmer, Paice Stemmer, etc. Chacun a sa propre façon de récupérer le stemma (racine) d’un mot.
La plupart de ces algorithmes fonctionnent avec la langue anglaise.
Il existe cependant des algorithmes de stemming qui ont été implémentés pour le Français et la bibliothèque NLTK de Python dispose d’un Stemmer en français.
Testons ce Stemmer avec une phrase issue de La Longue Marche de Stephen King :
Ils marchaient dans l’obscurité pluvieuse comme des fantômes décharnés, et Garraty n’aimait pas les regarder. C’étaient des morts-vivants.
Après l’avoir passé au Stemmer de NLTK nous obtenons le résultat suivant :
il march dan l’obscur pluvieux comm de fantôm décharnes et garraty n’aim pas le regarder c’et de morts-vivants
En lisant les résultats après l’extraction, vous pouvez clairement voir qu’après avoir réduit les mots, il y en a plusieurs qui n’existent pas dans le dictionnaire Français : fantom,aim,….
À la raison pour laquelle cela peut arriver, c’est la meilleure réponse que j’ai pu trouver en ligne :
Il est souvent considéré comme une erreur grossière qu’un algorithme de stemming ne laisse pas un mot réel après avoir enlevé la tige. Mais le but du Stemming est de rassembler les différentes formes d’un mot, et non de faire correspondre un mot à sa forme ‘paradigmatique’. Source
En résumé, le Stemming sert donc à regrouper de manière “brute” plusieurs mots partageant le même sens en enlevant le genre, le nombre, la conjugaison, etc.
Les algorithmes ne sont pas, cependant, parfaits. Ils peuvent marcher pour certains cas et pour d’autres, regrouper des mots ne partageant pas le même sens.
PS : Le stemming n’est pas un concept applicable à toutes les langues. Il n’est pas, par exemple, applicable en chinois. Mais pour les langues du groupe indo-européen un modèle commun de structure des mots émerge. En supposant que les mots sont écrits de gauche à droite, la tige ou la racine d’un mot est à gauche, et zéro ou plusieurs suffixes peuvent être ajoutés à droite. Source
Lemmatisation
En linguistique informatique, la lemmatisation est le processus algorithmique qui consiste à déterminer le lemme d’un mot en fonction de sa signification prévue.( Wikipedia )
Dans de nombreuses langues, les mots apparaissent sous plusieurs formes infléchies. Par exemple, en anglais français, le verbe marcher peut apparaître comme marchera, marché, marcheront , etc. La forme de base « marcher », que l’on pourrait trouver dans un dictionnaire, s’appelle le lemme du mot.
Ici, le but principal de la lemmatisation, est de regrouper les différents mots d’un texte qui partagent le même « sens » en un seul mot qui est le lemme sans pour autant créer de « nouveaux » mots comme ce qui se fait dans le cas du stemming.
Cependant, les lemmatizers sont beaucoup plus difficiles à créer parce que vous avez besoin d’un dictionnaire qui contient la plupart des mots dans votre langue et il faut aussi connaître la nature du mot en question : un verbe et un nom sont lemmatisés de façon différente.
Les moteurs de recherche peuvent aussi utiliser la lemmatisation au lieu du stemming, elle fournit dans certains cas des résultats plus précis mais est plus difficile à mettre en œuvre.
Comme pour le Stemming, NLTK possède aussi un lemmatizer pour le Français.
Tokenisation
Le traitement d’un gros morceau de texte n’est généralement pas la meilleure façon de procéder. Comme on dit toujours « diviser pour mieux régner ». Le même concept s’applique également aux tâches de NLP.
Lorsque nous avons des textes, nous les séparons en différents jetons et chaque jeton représente un mot. Il sera plus facile de traiter ( faire du stemming ou de la lemmatisation) et de filtrer les jetons inutiles (comme les caractères spéciaux ou les mots vides).
N-gramme
Un n-gramme est une séquence contiguë de n éléments d’un échantillon donné de texte. (Wikipedia)
Les n-grammes sont donc des séquences de mots formées à partir d’un texte. Ici N décrit le nombre de mots combinés ensemble.
Si vous aviez la phrase :
« c’est fini Anakin, j’ai l’avantage sur toi ! »
Chaque petit carré représente un jeton/token (mot/1-gram), ce qui est pratiquement la tokenisation de la phrase. Ainsi, la tokenisation peut être considérée comme un cas particulier de N-grammes où N=1.
Un 2-grammes aussi appelé bigrame de la même phrase produirait ceci :

Les N-grammes peuvent être utilisés pour savoir quelle séquence de mots est la plus courante. Comme ce site Web qui calcule les trigrammes les plus courants en français :
1-Gram | Occurrence | 2-Grams | Occurence | 3-Grams | Occurence |
de | 1024824 | de la | 132940 | il y a | 8903 |
la | 602084 | à la | 56794 | et de la | 4796 |
et | 563643 | et de | 37743 | il y avait | 4397 |
le | 411923 | dans la | 30090 | que je ne | 3894 |
Tableau :Analyse des n-grammes et de leur occurrence dans un corpus textuel
POS tagging
En linguistique corpus, le POS tagging (étiquetage POS ou étiquetage PoS ou POST), aussi appelé étiquetage grammatical ou désambiguïsation par catégorie de mots, est le processus de marquage d’un mot dans un texte (corpus) comme correspondant à une partie particulière du discours, selon sa définition et son contexte, c’est-à-dire sa relation aux mots voisins et connexes dans une phrase, un paragraphe, une phrase, etc. Une forme simplifiée de cette notion est couramment enseignée aux enfants d’âge scolaire, dans l’identification des mots comme les noms, les verbes, les adjectifs, les adverbes, etc. (Wikipédia)
Ainsi, le marquage POS est comme l’identification de la nature de chaque mot dans un texte.
C’est très utile, surtout en lemmatisation, car il faut savoir ce qu’est le mot avant d’essayer de le lemmatiser. Par exemple, la façon dont vous lemmatisez les noms et les verbes peut différer parce qu’ils expriment la pluralité ou le genre d’une manière différente.
Prenons notre même phrase d’exemple, après l’avoir passé à un POS tagger de Python, nous obtenons :
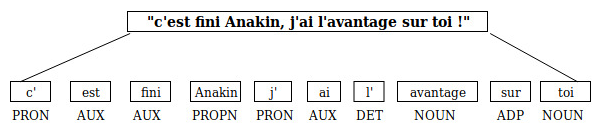
Il est également utile dans les tâches de traduction. Prenons cet exemple simple que j’ai trouvé en ligne :
I fish a fish .
Traduit en français vous avez :
je pêche un poisson.
Le mot “fish” a ici deux significations. Il fait référence au verbe to fish (pêcher) lorsqu’il est employé après un sujet et lorsqu’il suit un article, il fait référence au mot fish (poisson). Il est donc nécessaire de disposer d’un outil pour différencier les deux.
Il sera cependant très fastidieux de faire cette tâche dans un texte très long. Il existe des bibliothèques permettant de réaliser ce travail dans les langues telles que le Français ou l’Anglais. Il est aussi possible d’utiliser des techniques de Deep Learning pour réaliser ce travail.
Implémentation en Python
Nous allons maintenant essayer d’implémenter certaines de ces techniques dans le langage Python.
Pour cela, essayons de réaliser un exercice simple : prendre un livre et étudier ses mots et bigrammes les plus importants pour saisir de manière brève de quoi parle le livre.
Si vous n’aimez pas les codes, vous pouvez sauter cette partie et aller à la conclusion
Téléchargeons d’abord le livre Zadig de Voltaire à partir de la bibliothèque du projet Gunteberg.
[python]
zadig_response = requests.get(‘https://www.gutenberg.org/cache/epub/4647/pg4647.txt’)
zadig_data = zadig_response.text
# Chaque livre vient avec des licences qui ne nous intéressent pas vraiment donc on va enlever cette partie
zadig_data = zadig_data.split(‘*******’)[2]
[/python]
Nous définissons ensuite une fonction permettant de réaliser certaines des tâches de prétraitement :
[python]
def process_data(data):
#Mettons tous les mots du livre en minuscules
data = data.lower()
#Ne prendre que les lettres et les chiffres et supprimer tous les caractères spéciaux
pattern = r'[^a-zA-z0-9\s]’
data = re.sub(pattern, », data)
#Enlever tous les mots d’arrêt (stopwords) comme ‘les’, ‘du’, ……. et tokeniser le texte
stop_words = set(stopwords.words(‘french’))
stop_words.add(‘[‘)
stop_words.add(‘]’)
stop_words.add(‘les’)
stop_words.add(‘a’)
word_tokens = nltk.word_tokenize(data)
words = [w for w in word_tokens if not unidecode(w) in stop_words]
#supprimer tous les accents s’ils existent
data = unicodedata.normalize(‘NFKD’,data).encode(‘ascii’, ‘ignore’).decode(‘utf-8’, ‘ignore’)
#Creer un stemmer en français
fs = FrenchStemmer()
text_stems = [fs.stem(word) for word in words]
#Creer un lemmatiseur en français
lemmatizer = FrenchLefffLemmatizer()
text_lemms = [lemmatizer.lemmatize(word,’v’) for word in words]
return (text_stems, text_lemms)
[/python]
Ensuite nous comptons les mots les plus fréquents dans le texte d’abord pour le texte passé par un Stemmer :
[python]
#Comptons maintenant les mots pour les lemmes et les stems
text_stems,text_lems = process_data(zadig_data)
count = Counter(text_stems)
print(‘Les mots les plus utilisés dans Zadig avec les stems :’)
for word in count.most_common(15):
print (word)
[/python]

Pour les mots passés par un Lemmatizer :
[python]
count = Counter(text_lems)
print(‘Les mots les plus utilisés dans Zadig avec les lemmes :’)
for word in count.most_common(15):
print (word)
[/python]

Juste pour le fun, comptons les bigrammes les plus fréquents :
[python]
ngram_counts = Counter(ngrams(text_lems, 2))
print(‘ les 10 bigrams les plus fréquents : ‘)
for word in ngram_counts.most_common(10):
print (word)
[/python]

En conclusion
Nous avons passé en revue les principales méthodes de pré traitement de données textuelles, elles sont utilisées pour faciliter la traduction d’un texte écrit en langage humain en langage machine.
La plus grande remarque faite lors des recherches pour cet article est que la plupart de ces techniques n’existent que pour les langues principales et ne sont « parfaites » que pour l’Anglais en général. Pour des langues moins fournies, telle que le Wolof, il devient primordial de pouvoir mettre en place toutes ces techniques pour pouvoir traiter de manière efficace des textes écrits à l’aide de ces dernières.
N’hésitez pas à lire notre article sur les fondements du NLP et du deep learning.
Si vous souhaitez nos prochains articles sur le sujet, cliquez ici !